目录
10.3.4 Spark运行原理
1.设计背景
2.RDD概念
3.RDD特性
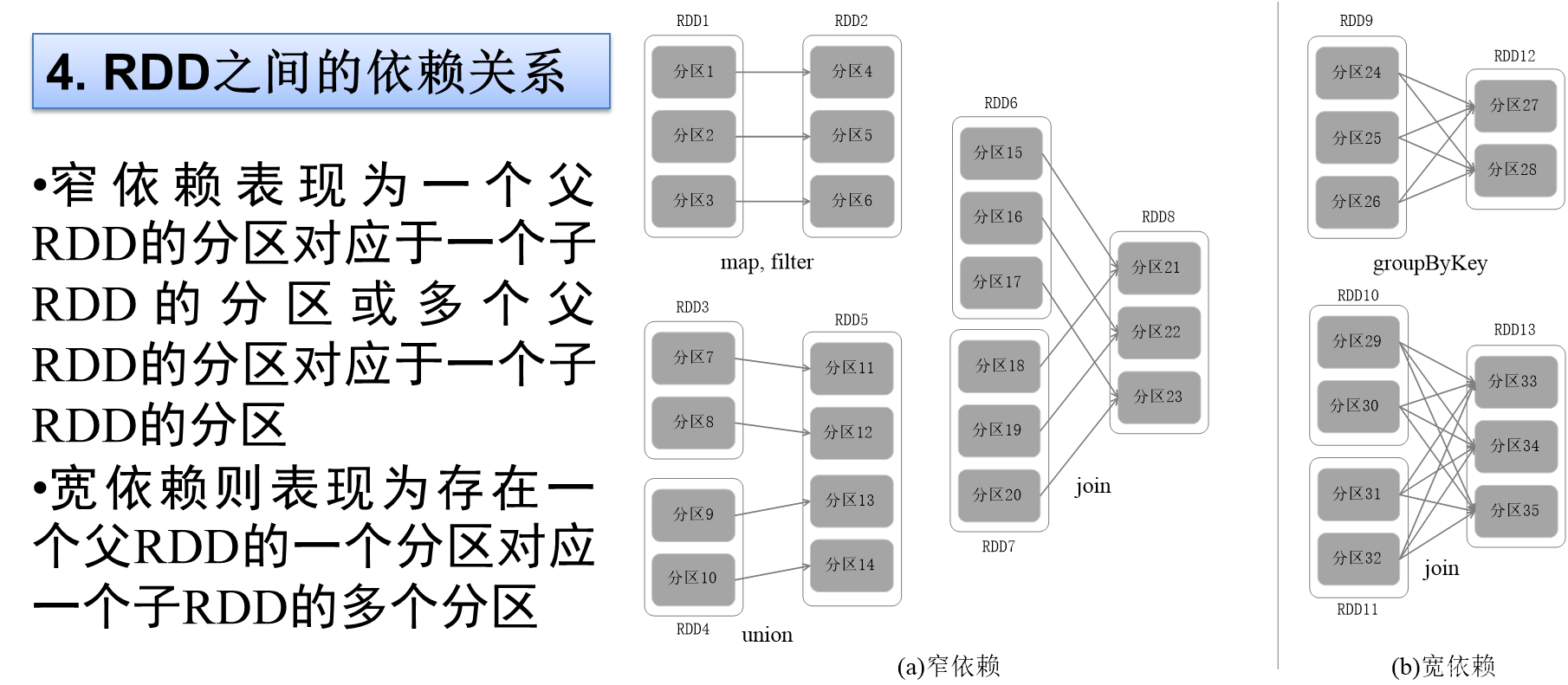
4.RDD之间的依赖关系
窄依赖和宽依赖
5.Stage的划分
Stage的类型包括两种:ShuffleMapStage和ResultStage
6.RDD运行过程
10.3.4 Spark运行原理
1.设计背景
RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储,大大降低了数据复制、磁盘IO和序列化开销。
2.RDD概念
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和group by)而创建得到新的RDD
RDD采用了惰性调用:RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于行动之前的所有“转换”操作,Spark只是会记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互依赖关系,而不会触发真正的计算。
上述这一系列处理称为一个“血缘关系(Lineage)”,即DAG拓扑排序的结果。采用惰性调用,通过血缘关系连接起来的一系列RDD操作就可以实现管道化(pipeline),避免了多次转换操作之间数据同步的等待,而且不用担心有过多的中间数据,因为这些具有血缘关系的操作都管道化了,一个操作得到的结果不需要保存为中间数据,而是直接管道式地流入到下一个操作进行处理。
同时,这种通过血缘关系把一系列操作进行管道化连接的设计方式,也使得管道中每次操作的计算变得相对简单,保证了每个操作在处理逻辑上的单一性;相反,在MapReduce的设计中,为了尽可能地减少MapReduce过程,在单个MapReduce中会写入过多复杂的逻辑。
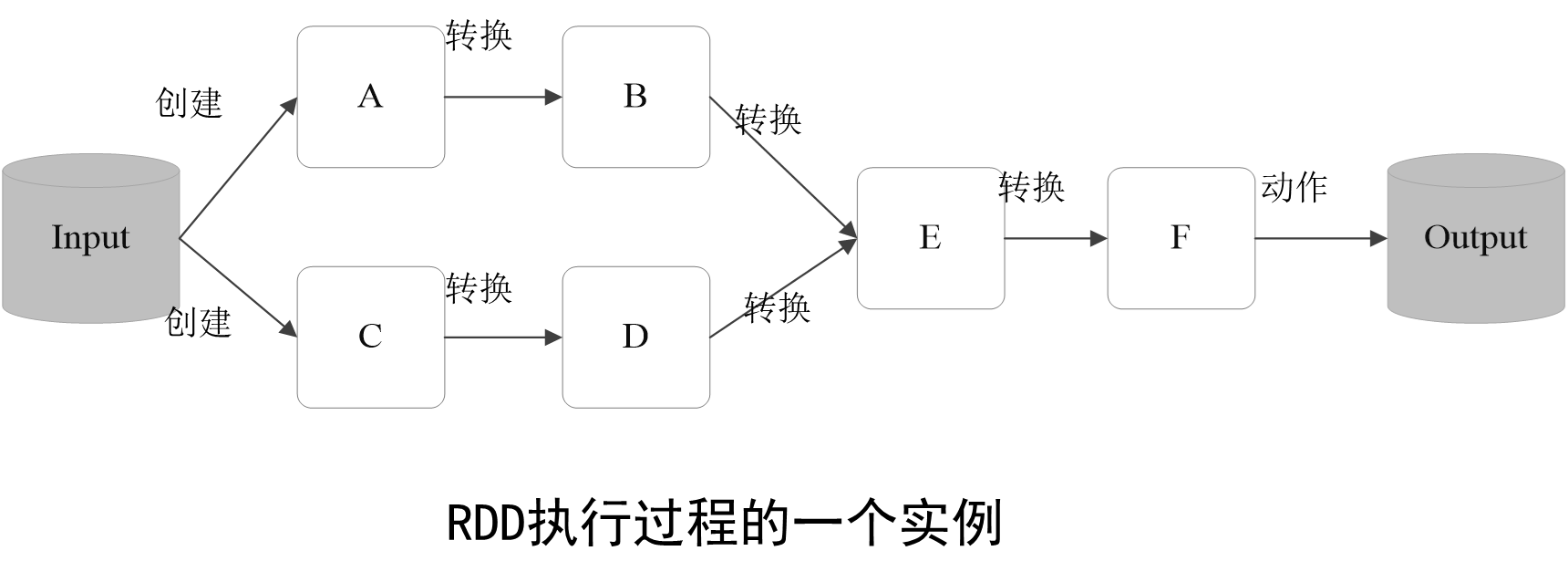
一个Spark的“Hello World”程序:以一个“Hello World”入门级Spark程序来解释RDD执行过程,这个程序的功能是读取一个HDFS文件,计算出包含字符串“Hello World”的行数。





3.RDD特性
Spark采用RDD以后能够实现高效计算的原因主要在于:
(1)高效的容错性
现有容错机制:数据复制或者记录日志
RDD:血缘关系、重新计算丢失分区、无需回滚系统、重算过程在不同节点之间并行、只记录粗粒度的操作
(2)中间结果持久化到内存,数据在内存中的多个RDD操作之间进行传递,避免了不必要的读写磁盘开销
(3)存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化
4.RDD之间的依赖关系
RDD不同操作,会使得RDD分区之间产生不同的依赖关系,DAG调度器根据RDD之间的依赖关系,把DAG划分为若干个阶段,依赖关系分为窄依赖和宽依赖,二者主要区别:是否包含Shuffle操作。
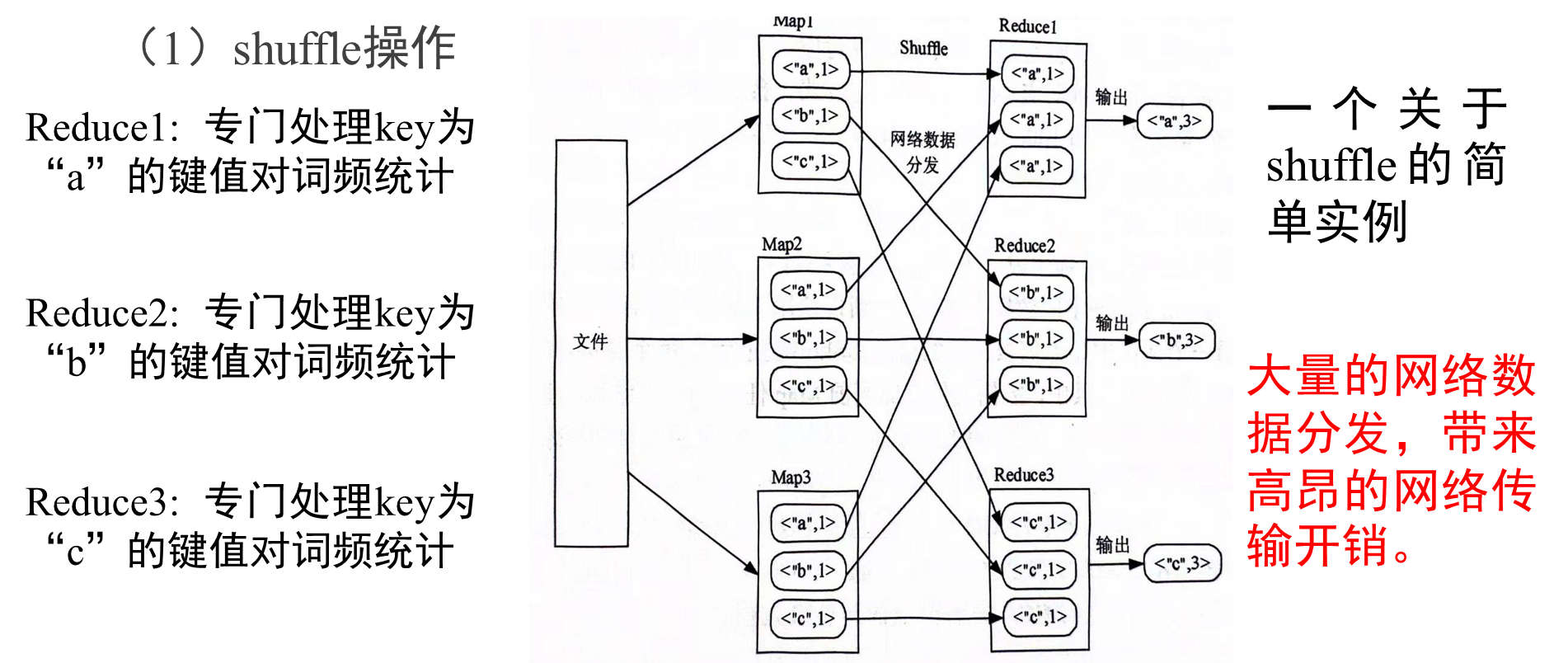
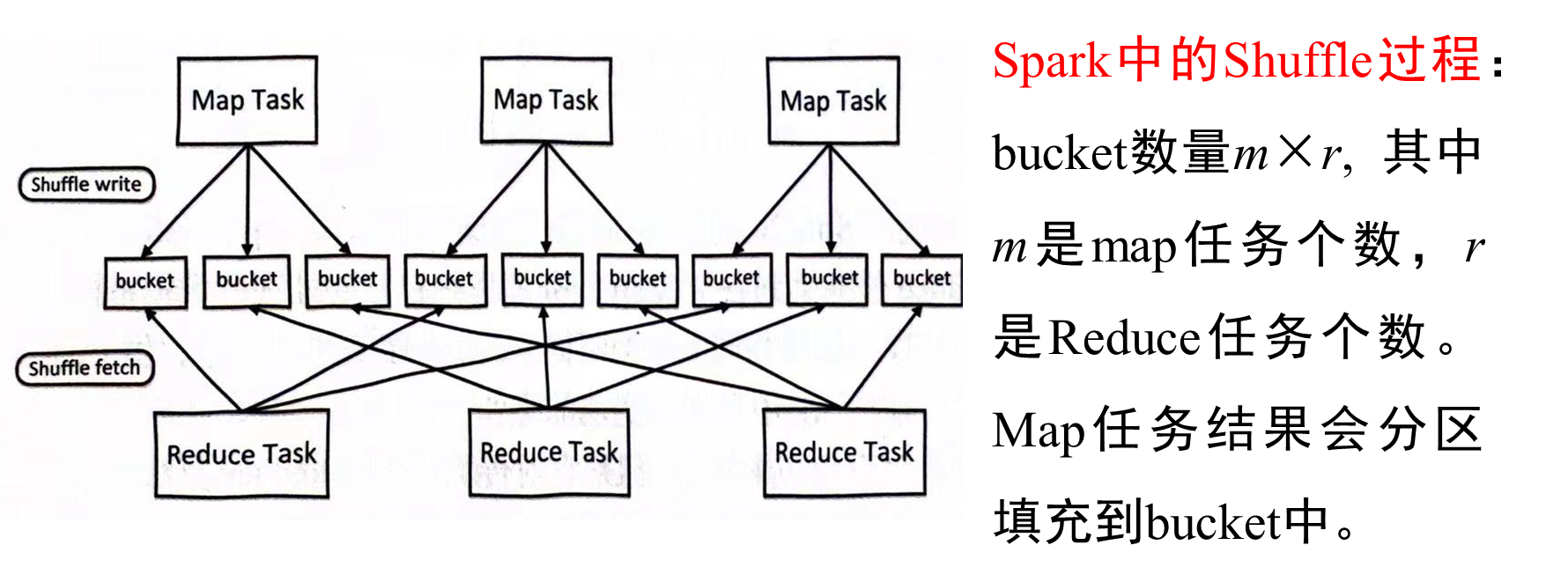
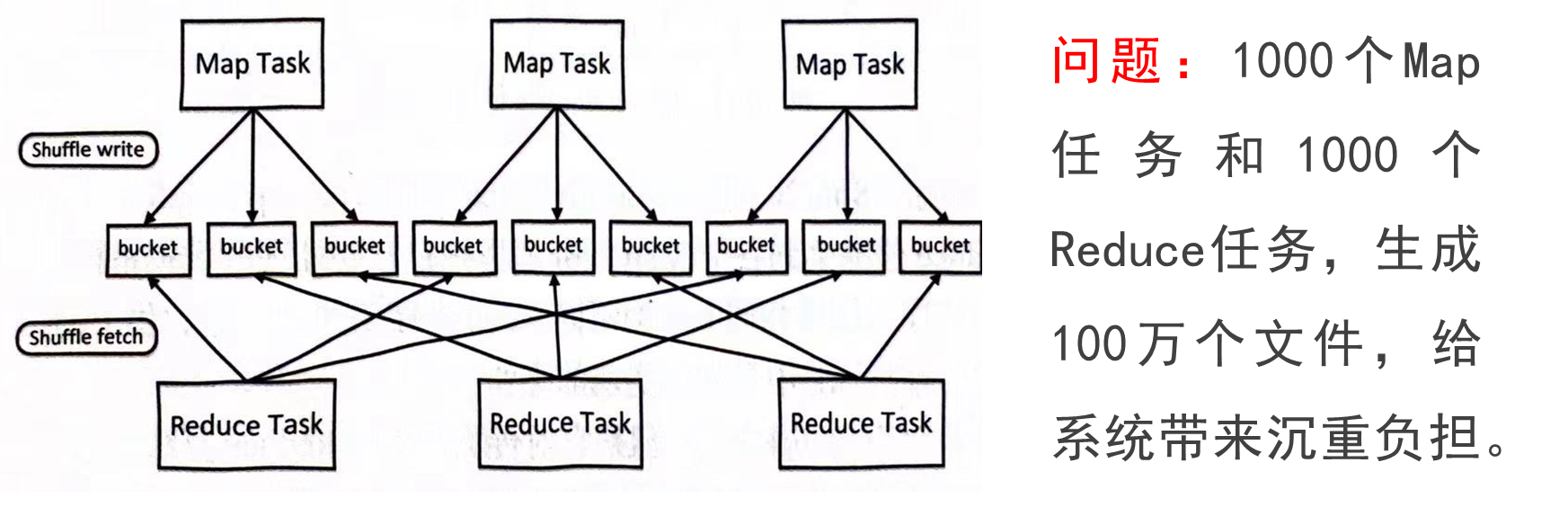
窄依赖和宽依赖
5.Stage的划分
Spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分Stage,具体划分方法是:
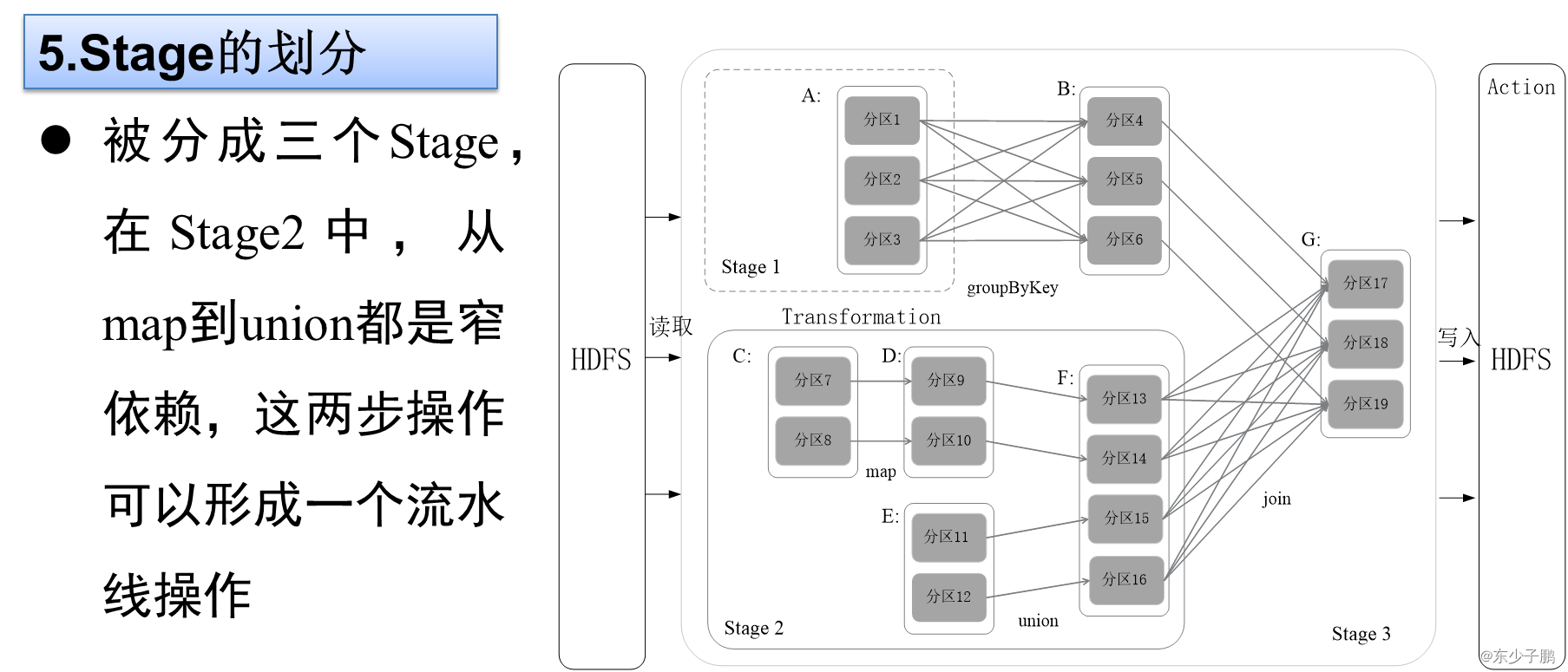
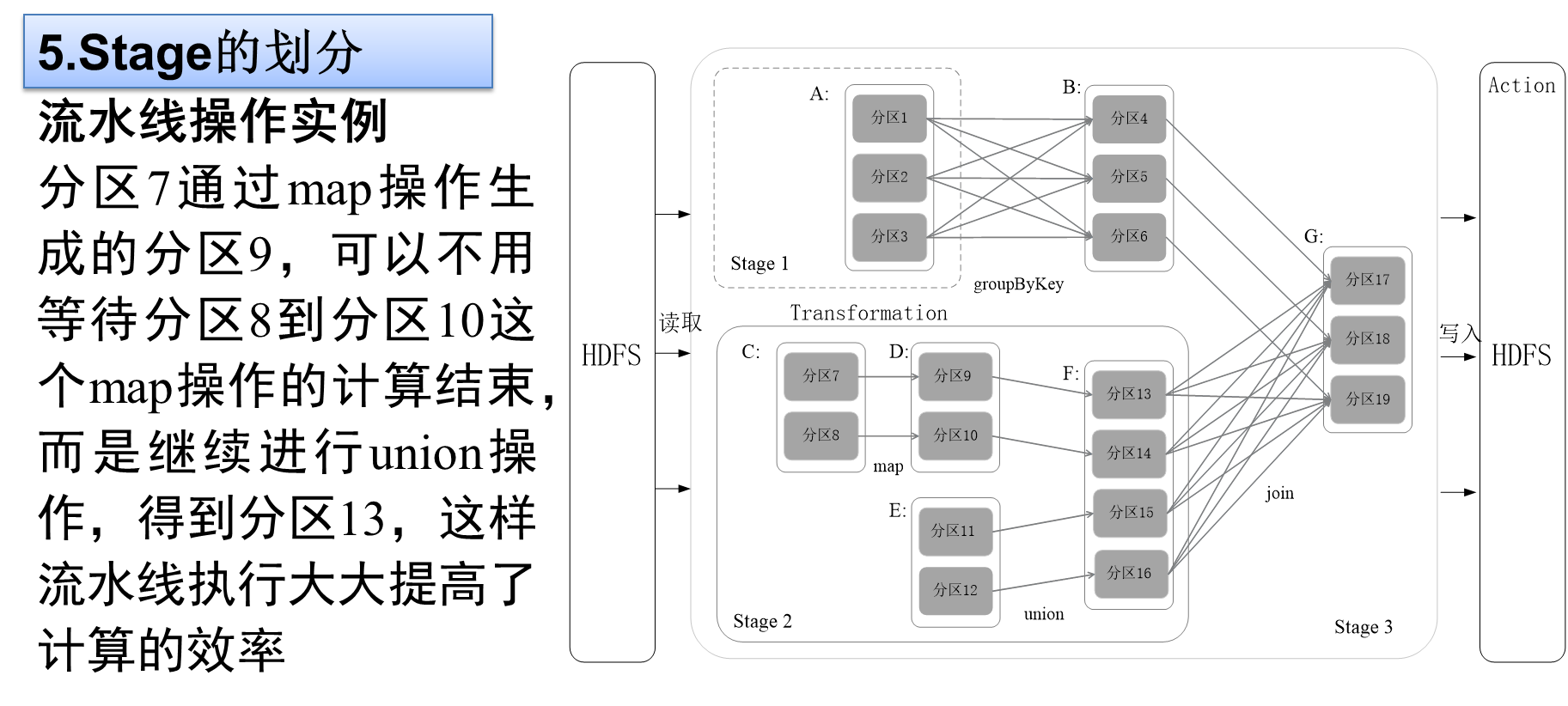
Stage的类型包括两种:ShuffleMapStage和ResultStage
(2)ResultStage:最终的Stage,没有输出,而是直接产生结果或存储。这种Stage是直接输出结果,其输入边界可以是从外部获取数据,也可以是另一个ShuffleMapStage的输出。在一个Job里必定有该类型Stage。
因此,一个Job含有一个或多个Stage,其中至少含有一个ResultStage。
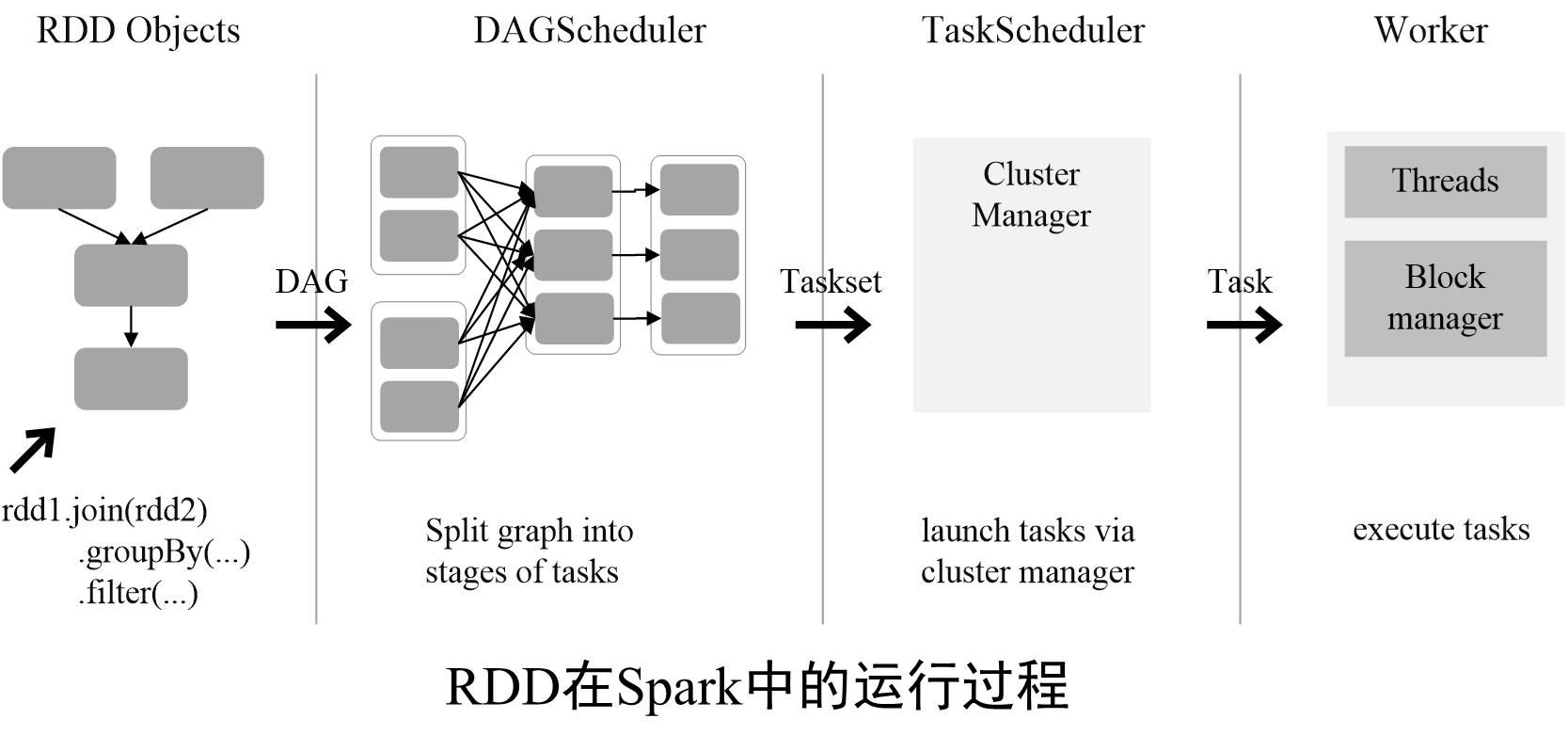
6.RDD运行过程
通过上述对RDD概念、依赖关系和Stage划分的介绍,结合之前介绍的Spark运行基本流程,再总结一下RDD在Spark架构中的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。



![[leetcode]beautiful-arrangement. 优美的排列](https://img-blog.csdnimg.cn/direct/deea55b88eab4af5909ef37672862aa8.png)